Nama/NIM : I Wayan Cita Ekayana/1304505085
Jurusan/Fakultas/Perguruan Tinggi : Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah : Data Warehouse
Dosen : I Putu Agus Eka Pratama, S.T., M.T.
Data Warehouse dan Big Data
Data Warehouse
Data Warehouse adalah database yang didesain khusus untuk mengerjakan proses query, membuat laporan dan analisa. Data yang di simpan adalah data business history dari sebuah organisasi /perusahaan, dimana data tersebut tidak tersimpan secara rinci/detil. Sehingga data dapat bertahan lebih lama berbeda dengan data OLTP (Online Transactional Processing) yang tersimpan sampai prosesnya berlangsung secara lengkap.
Sumber data pada datawarehouse berasal dari berbagai macam format, software, platform dan jaringan yang beda. Data tersebut adalah hasil dari proses transaksi perusahan / organisasi sehari.hari. Karena berasal dari sumber yang berbeda beda tadi, maka data pada data warehouse harus tersimpan dalam sebuah format yang baku.
Data Warehouse juga merupakan salah satu sistem pendukung keputusan, yaitu dengan menyimpan data dari berbagai sumber, mengorganisasikannya dan dianalisa oleh para pengambil kebijakan. Akan tetapi datawarehouse tidak dapat memberikan keputusan secara langsung. Namun ia dapat memberikan informasi yang dapat membuat user menjadi lebih paham dalam membuat kebijakan strategis.
Adapun karakteristik umum yang dimiliki datawarehouse adalah :
- Data terintegrasi dari berbagai sumber yang berasal dari proses transaksional (OLTP)
- Data dibuat konsisten
- Merupakan aggregate data/kesimpulan data, bukan data yang terperinci
- Data bertahan lebih lama
- Data tersimpan dalam format yang tepat sehinngga proses query dan analisa dapat dilakukan dengan cepat
- Data bersifat read only
Big Data
Menurut (Eaton, Dirk, Tom, George, & Paul) Big Data merupakan istilah yang berlaku untuk informasi yang tidak dapat diproses atau dianalisis menggunakan alat tradisional.
Menurut (Dumbill, 2012) , Big Data adalah data yang melebihi proses kapasitas dari kovensi sistem database yang ada. Data terlalu besar dan terlalu cepat atau tidak sesuai dengan struktur arsitektur database yang ada. Untuk mendapatkan nilai dari data, maka harus memilih jalan altenatif untuk memprosesnya.
Berdasarkan pengertian para ahli di atas, dapat disimpulkan bahwa Big Data adalah data yang memiliki volume besar sehingga tidak dapat diproses menggunakan alat tradisional biasa dan harus menggunakan cara dan alat baru untuk mendapatkan nilai dari data ini.
 Gambar Big Data
Gambar Big Data
(Sumber :jcii.blog.binusian.org/…/BIG–DATA–JESSICA-06-PEM-1501189785.doc/halaman 5)
Big Data mengacu pada dataset yang ukurannya diluar kemampuan dari database software tools untuk meng-capture, menyimpan,me-manage dan menganalisis. Definisi ini sengaja dibuat subjective agar mampu digabungkan oleh definisi Big Data yang masi belum ada baku. Ukuran big data sekitar beberapa lusin TeraByte sampai ke beberapa PetaByte tergantung jenis Industri Isi dari Big Data adalah Transaksi+interaksi dan observasi atau bisa di bilang segalanya yang berhubungan dengan jaringan internet, jaringan komunikasi, dan jaringan satelit.
Big data dapat di artikan kedalam 9 karakter (IBM) menurut responden sehingga disimpulkan oleh IBM, Big data adalah data yang memiliki scope informasi yang sangat besar, model informasi yang real-time, memiliki volume yang besar, dan berasalkan social media data jadi dapat disimpulkan bahwa Big data adalah dataset yang memiliki volume besar dan salah satu isinya berdasarkan social media data, dan informasi dari Big data selalu yang terbaru (latestdata) sehingga model informasi nya real-time, dan scope informasi nya tidak terfocus pada industri-indrustri kecil saja atau industri-indrustri besar saja melainkan semuanya baik industry kecil maupun besar.
 Gambar karakter dalam Big Data
Gambar karakter dalam Big Data
(Sumber :jcii.blog.binusian.org/…/BIG–DATA–JESSICA-06-PEM-1501189785.doc/halaman 6)
Dimensi-dimensi Big Data
Ada 3 dimensi awal dalam Big Data yaitu 3V: Volume, Variety dan Velocity. Berikut penjelasan dari masing-masing dimeni tersebut.

Gambar Dimensi pada Big Data
(Sumber :jcii.blog.binusian.org/…/BIG–DATA–JESSICA-06-PEM-1501189785.doc/halaman 7)
- Volume
perusahaan tertimbun dengan data yang terus tumbuh dari semua jenis sektor, dengan mudah mengumpulkan terabyte bahkan petabyte-informasi.
- Mengubah 12 terabyte Tweet dibuat setiap hari ke dalam peningkatan sentimen analisis produk.
- Mengkonvert 350 milliar pembacaan tahunan untuk lebih baik dalam memprediksi kemampuan beli pasar.
Mungkin karakteristik ini yang paling mudah dimengerti karena besarnya data. Volume juga mengacu pada jumlah massa data, bahwa organisasi berusaha untuk memanfaatkan data untuk meningkatkan pengambilan keputusan yang banyak perusahaan di banyak negara. Volume data juga terus meningkat dan belum pernah terjadi sampai sethinggi ini sehingga tidak dapat diprediksi jumlah pasti dan juga ukuran dari data sekitar lebih kecil dari petabyte sampai zetabyte. Dataset big data sekitar 1 terabyte sampai 1 petabyte perperusahaan jadi jika big data digabungkan dalam sebuah organisasi / group perusahaan ukurannya mungkin bisa sampai zetabyte dan jika hari ini jumlah data sampai 1000 zetabyte, besok pasti akan lebih tinggi dari 1000 zetabyte.
- Variety
Volume data yang banyak tersebut bertambah dengan kecepatan yang begitu cepat sehingga sulit bagi kita untuk mengelola hal tersebut. Kadang-kadang 2 menit sudah menjadi terlambat. Untuk proses dalam waktu sensitif seperti penangkapan penipuan, data yang besar harus digunakan sebagai aliran ke dalam perusahaan Anda untuk memaksimalkan nilainya.
- Meneliti 5 juta transaksi yang dibuat setiap hari untuk mengidentifikasi potensi penipuan
- Menganalisis 500 juta detail catatan panggilan setiap hari secara real-time untuk memprediksi gejolak pelanggan lebih cepat.
Berbagai jenis data dan sumber data. Variasi adalah tentang mengelolah kompleksitas beberapa jenis data, termasuk structured data, unstructured data dan semi-structured data. Organisasi perlu mengintegrasikan dan menganalisis data dari array yang kompleks dari kedua sumber informasi Traditional dan non traditional informasi, dari dalam dan luar perusahaan. Dengan begitu banyaknya sensor, perangkat pintar (smart device) dan teknologi kolaborasi sosial, data yang dihasilkan dalam bentuk yang tak terhitung jumlahnya, termasuk text, web data, tweet, sensor data, audio, video, click stream, log file dan banyak lagi.
- Velocity :
Big Data adalah setiap jenis data – data baik yang terstruktur maupun tidak terstruktur seperti teks, data sensor, audio, video, klik stream, file log dan banyak lagi. Wawasan baru ditemukan ketika menganalisis kedua jenis data ini bersama-sama.
- Memantau 100 video masukan langsung dari kamera pengintai untuk menargetkan tempat tujuan.
- Mengeksploitasi 80% perkembangan data dalam gambar, video, dan dokumen untuk meningkatkan kepuasan pelanggan.
Data dalam gerak. Kecepatan di mana data dibuat, diolah dan dianalisis terus menerus. Berkontribusi untuk kecepatan yang lebih tinggi adalah sifat penciptaan data secara real-time, serta kebutuhan untuk memasukkan streaming data ke dalam proses bisnis dan dalam pengambilan keputusan. Dampak Velocity latency, jeda waktu antara saat data dibuat atau data yang ditangkap, dan ketika itu juga dapat diakses. Hari ini, data terus-menerus dihasilkan pada kecepatan yang mustahil untuk sistem tradisional untuk menangkap, menyimpan dan menganalisis. Jenis tertentu dari data harus dianalisis secara real time untuk menjadi nilai bagi bisnis.
Infrastruktur dalam Big Data
- High Performance Computing Cluster (HPCC) atau dapat disebut sebagai Data Analytics Supercomputer (DAS)
- Hadoop Platform (Map Reduced-Based Platform)
Dari kedua pendekatan teknologi tersebut terdapat perbedaan yang cukup signifikan (dari segi fungsi) dan juga terdapat kemiripan dalam proses yang berjalan didalamnya. Kemiripan dari dua teknologi tersebut adalah sama-sama memanfaatkan lebih dari satu komputer dalam melakukan proses penarikan informasi ataupun pemrosesan berbagai informasi atau bahkan dapat terlihat keduanya menggunakan konsep kluster pada arsitektur teknologi yang digunakan. Pada dasarnya keduanya pun dapat diintegrasikan dengan baik guna saling mendukung satu sama lain.
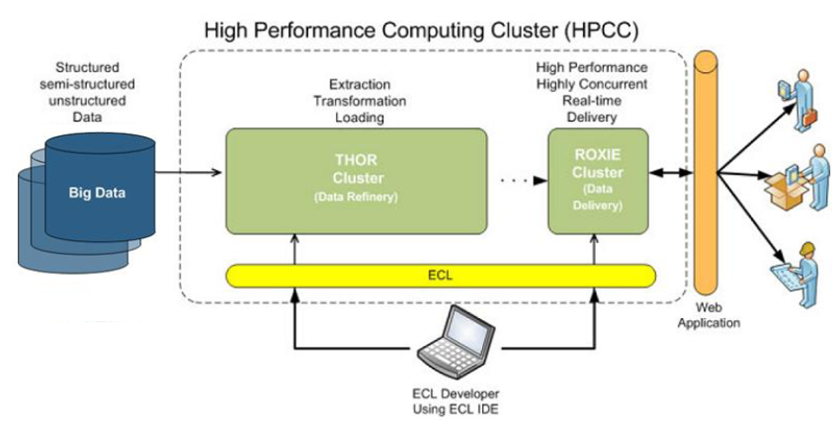
High Performance Compputing Clusters ini sendiri pada dasarnya membangun suatu super komputer yang terdiri dari lebih dari satu komputer dengan spesifikasi tertentu (biasanya sama) untuk saling membantu menopang, atau membagi tugas satu sama lain sehingga bersama-sama dapat melakukan processing terhadap suatu data, terutama dalam hal pencarian data. Proses besar yang biasanya berjalan sendiri adalah seperti, Ekstrak, Transform, dan Load, lalu setelah itu dilakukan analisis untuk mendapatkan informasi yang lebih sesuai dengan kebuthan bisnis organisasi tersebut.

Gambar High Performance Computing Cluster
(Sumber :https://situkangsayur.files.wordpress.com/2014/01/screenshot-from-2014-01-04-173403.png)
Sedangkan Hadoop Platform sendiri merupakan suatu project teknologi yang dikembangkan oleh apache dalam mengelola data besar sehingga jauh lebih efektif dan efisien. Dalam hadoop sendiri terdiri dari berbagai komponen, bahkan hingga hadoop sendiri memiliki distributed file system sendiri yang disebut dengan (HDFS). Kelebihan dari dari HDFS ini sendiri adalah :
- Fault tolerance, dan di-deploy untuk low cost hardware
- Write Onece, Read many, merupakan koherensi sederhana, dan terlebih lagi framework yang dibangun dalam hadoop ketika kita akan menggunakan hadoop, menggunakan teknologi java.
- Memindahkan komputasi/proses lebih cepat dari memindahkan data.
- Mirip Google File System, tetapi HDFS membagi file menjadi block dalam cluster node yang terdistribusi.
- Core component : master vs slave, name node vs data node, job tracker vs task tracker.

Gambar arsitektur integrasi antara HPCC dan Hadoop platform
(Sumber:https://situkangsayur.files.wordpress.com/2014/01/screenshot-from-2014-01-04-173441.png)
- Analisa data (OLAP)
OLAP (Online Analytical Proccessing) merupakan suatu proses yang digunakan untuk melakukan permintaan terhadap data dalam bentuk yang kompleks dan menganalisa data yang bervolume besar. OLAP merupakan teknologi yang memproses data di dalam database dalam struktur multidimensi, menyediakan jawaban yang cepat untuk query dan analisis yang kompleks. Data multidimensi adalah data yang dapat dimodelkan sebagai atribut dimensi dan atribut ukuran. Contoh atribut dimensi adalah nama barang dan warna barang, sedangkan contoh atribut ukuran adalah jumlah barang.
- OLTP
OLTP (Online Transactional Processing) merupakan sekumpulan fungsi yang bekerja secara bersama-sama dalam mengelola, mengumpulkan, menyimpan, memproses serta mendistribusikan informasi. OLTP (On-line Transaction Processing) memiliki karakteristik dengan jumlah data yang besar namun transaksi yang dilakukan cukup sederhana seperti insert,update, dan delete. Hal utama yang menjadi perhatian dari sistem yang dilakukan OLTP adalah melakukan query secara cepat, data mudah untuk diperbaiki dan dapat diakses melalui komputer yang terhubung dalam jaringan. OLTP berorientasi pada proses yang memproses suatu transaksi secara langsung melalui komputer yang terhubung dalam jaringan. Seperti misalanya kasir pada sebuah super market yang menggunakan mesin dalam proses transaksinya. OLTP mempunyai karakteristik beberapa user dapat creating, updating, retrieving untuk setiap record data.
- Data Mining
Secara sederhana data mining adalah suatu proses untuk menemukan interesting knowledge dari sejumlah data yang di simpan dalam basis data atau media penyimpanan data lainnya. Dengan melakukan data mining terhadap sekumpulan data, akan didapatkan suatu interesting pattern yang dapat disimpan sebagai knowledge baru.Pattern yang didapat akan digunakan untuk melakukan evaluasi terhadap data data tersebut untuk selanjutnya akan didapatkan informasi.
- ETL (Extraction, Transformation, Loading)
Tiga fungsi utama yang perlu dilakukan untuk membuat data siap digunakan pada datawarehouse adalah extraction, transformation dan loading. Ketiga fungsi ini terdapat pada staging area. Pada data staging ini, disediakan tempat dan area dengan beberapa fungsi seperti data cleansing, change, convert, dan menyiapkan data untuk disimpan serta digunakan oleh datawarehouse.
- Extraction
Data Extraction adalah proses pengambilan data yang diperlukan dari sumber datawarehouse dan selanjutnya dimasukkan pada staging area untuk diproses pada tahap berikutnya [2]. Pada fungsi ini, kita akan banyak berhubungan dengan berbagai tipe sumberdata. Format data, mesin yang berbeda, software dan arsitektur yang tidak sama. Sehingga sebelum proses ini kita lakukan, sebaiknya perlu kita definisikan requirement terhadap sumber data yang akan kita butuhkan untuk lebih memudahkan pada extraction data ini.
- Transformation
Pada kenyataannya, pada proses transaksional data disimpan dalam berbagai format sehingga jarang kita temui data yang konsisten antara aplikasi-aplikasi yang ada. Transformasi data ditujukan untuk mengatasi masalah ini. Dengan proses transformasi data ini, kita melakukan standarisasi terhadap data pada satu format yang konsisten. Beberapa contoh ketidakkonsistenan data tersenut dapat diakibatkan oleh tipe data yang berbeda, data length dan lain sebagainya
Keterangan :
- Format, Pada transaksional data dapat disimpan dalam berbagai format. Elemen data tersebut dapat tersimpan dalam format text, integer dan sebagainya. Untuk itu standarisasi perlu dilakukan dengan melihat kegunaan pokok dari elemen data pada proses transaksinal dan datawarehouse.
- Description, Pada tabel terlihat representasi ketiga nama pelanggan adalah sama. Namun dengan penulisan yang beda terlihat adanya perbedaan format pada data. Oleh karena itu perlu diambil salah satu dari deskripsi tersebut untuk konsistensi data.
- Unit, Adanya perbedaan satuan ukuran dapat menimbulkan permasalahan yang komplek. Jika user tidak mengetahui adanya perbedaan ini dan menganggap sama, maka akan terjadi kesalahan ketika kita melakukan penghitungan matematis.
- Encoding, huruf atau nomor dapat dijadikan label sebagi identifikasi suatu objek. Seperti pada tabel diatas, kesalahan dapat terjadi karenanya.
- Loading
Data loading adalah memindahkan data ke datawarehouse. Ada dua loading data yang di lakukan pada datawarehouse. Pertama adalah inisial load, proses ini dilakukan pada saat telah selesai mendesign dan membangun data warhouse. Data yang masukkan tentunya akan sangat besar dan memakan waktu yang relatif lebih lama. Kedua Incremental load, dilakukan ketika data warehouse telah dioperasikan. Sehingga akan lebih mudah melakukan data extraction, transformation dan loading terhadap data tersebut.
Daftar Pustaka
[1]Yasid, Ahmad. 2010. (Data Warehouse). from. (https://achmadyasid.files.wordpress.com/2010/03/datawarehouse.doc)
[2]Anonim. 2014. (arsitektur Umum Big Data). from (https://openbigdata.wordpress.com/2014/…/arsitektur-umum-dari-big-data)
[3]Kharisma, Hendri. 2014. (Infrastruktur Big Data). from (https://situkangsayur.wordpress.com/2014/01/04/infrastruktur-big-data/)
[4]Jessica. 2013. (Pengenalan Big Data). from (jcii.blog.binusian.org/…/BIG–DATA–JESSICA-06-PEM-1501189785.doc)

{kind=link}
{kind=link}